

【Shopifyストア運用支援】巨大な商品マスタXMLをCSVに変換する
サービス内容や事例など | ご相談・お見積りはお気軽に |
先日、マーケティング担当の方から「クライアントに商品マスタのデータを預かったのですが、Excelで開けないので何とかなりませんか?」との相談を受けました。ファイルの拡張子は .xml でファイルサイズは1ギガバイト近くあります。試しに、Excelのメニューから「データ」-「その他のデータソース」-「XML データインポート」を選択して、商品マスタのファイルを指定します。結果、5分ほど待っても商品マスタを表示することはできませんでした。ちなみに、筆者のノートPCのスペックは iCore3 第6世代の 2.3GHzでメモリは 8ギガバイトと、高性能なものではありませんが、ECサイトのオペレーションで使うパソコンとしては至って普通じゃないでしょうか。そこで、巨大な XML形式の商品マスタを CSVに変換するツールを Pythonで作成してみました。
XML形式の商品マスタを Pythonで CSV形式に変換する
基本は、下記の 14行(空行・コメント行を除く)ほどのコードで XML→CSV変換ができます。
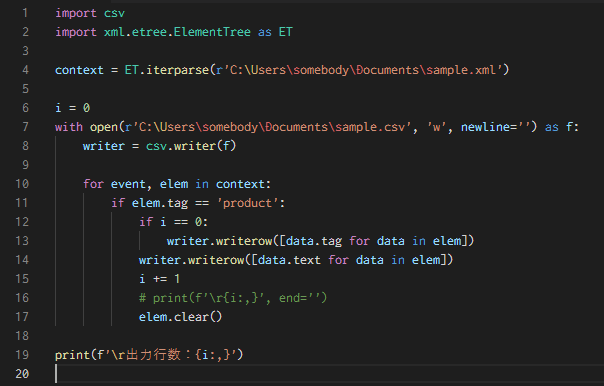
この Pythonプログラムをコマンドプロンプトから実行するとこんな感じです。
筆者のPCでは、10万件の商品情報を平均約 4秒で CSV形式に変換することができました。

Pythonの対話モード(インタラクティブモード)で試す
上述のコードを Pythonの対話モード(インタラクティブモードともいいます)で試してみましょう。コマンドプロンプトで pythonと入力すると Pythonの対話モードが起動します。Pythonがまだインストールされていない場合は Pythonをインストールしてください。(Pythonのインストールについては後日掲載する予定です)
「>>>」と表示されている部分をプロンプトといいますが、ここに Pythonの命令を入力していきます。
まず、XML形式のファイルを CSV形式のファイルに変換して出力するので、「csv」と「xml.etree.ElementTree」の2つのモジュールをインポートします。
モジュールとはあらかじめ作成されたプログラムのかたまりのようなもので、パッケージやライブラリなどとも呼ばれます。厳密な呼び方はとりあえずスルーして、ここではモジュールといいます。またインポートとは、モジュールを呼び出して、これから作成・実行するプログラムで使えるようにする命令です。
「import xml.etree.ElementTree」は「xml」の子どもの「etree」の子どもの「ElementTree」を呼び出しているイメージです。「import xml」と書いても問題はありませんが、「xml」という家族ごとインポートすると、呼出時間がかかったり、必要以上にメモリを消費するため好ましくありません。また、「xml」という家族ごとインポートした場合は、孫の「ElementTree」の 「iterparse」メソッド(関数)を使いたいとき、「xml.etree.ElementTree.iterpaese」と冗長なコードになってしまうデメリットもあります。
csvとxml.etree.ElementTreeの詳細は以下のURLをご覧ください。
xml.etree.ElementTreeの iterpaese関数に XMLファイルを渡して、解析結果を変数 contextに代入します。XMLファイルのパスの先頭についている「r」は raw文字列を示すもので、これで示される文字列はバックスラッシュ(\)がエスケープされません。
ここで、「xml.etree.ElementTree.iterparse」について前述のドキュメントURLの説明を確認してみましょう。

(引用元:https://docs.pyhon/ja/3/library/xml.etree.elementtree.html)
xml.etree.ElementTree.iterparse(独自訳)
XMLのセクションを段階的に要素ツリーへと解析して、その結果をユーザに返します。「source」は XMLデータを含むファイル名かファイルオブジェクトです。「events」は対象とするイベントを指定します。サポートされているイベントは "start"、"end"、"comment"、"pi"、"start-ns"、"end-ns"の各文字列です(「ns」イベントは詳細な名前空間情報を取得するために使用されます)。「events」が省略されたときは "end" イベントのみが返されます。「parser」はオプションの解析インスタンスです。これを指定しなかった場合は、デフォルトの XMLParserが使用されます。「parser」は XMLParserのサブクラスでなければならず、またターゲットとしてデフォルトの TreeBuilderしか使えませんとややこしいことが書いてありますが、Python 3.4以降は非推奨となっているのでスルーします。結果には(event, elem)ペアを提示するイテレータが返されます。
つまり、iterparseに XMLファイルのパスと目的のイベント名を指定すると、指定したイベントに基づいて XMLの要素を抽出してくれます。 XMLの詳しい説明はここでは省きますが、簡単に言うと、下記のサンプルのようにタグでデータを囲むことでデータの構造とデータそのものを同時に表すものです。 データの前のタグを開始タグ、後のタグを終了タグといいますが、iterparse関数のイベントオプションは、"start"が開始タグ、"end"が終了タグを指します。また、"comment"はそのままXMLのコメント、"pi"は「Processing Instructions」の略で、つまり処理命令のタグをイベント対象とするという意味になります。
例えば、上記の XMLサンプルを使って「pi」要素の内容を調べたいときは、xml.etree.ElementTree.iterparseの eventsパラメータに 'pi' を指定します。なお、eventsパラメータのデータ型はタプルのため、「('pi',)」と記述します。Pythonの対話モードで実行すると「xml-stylesheet href="mystyle.css" type="text/css"」という結果が表示されます。
では、 "start" や "end" イベントではどうなるでしょうか?
イベントオプションが "start" のときは開始タグ、 "end" のときは終了タグが返されることが分かります。一見、データを取得するには "start" でも "end" でも同じように取れそうですが、注釈を読むと、開始タグの末尾の ">" までは保証され、属性は正しく取得することができるが、テキストやテイル属性、子要素は保証されないとのこと。つまり、下記のような XMLデータの場合、開始タグの「属性」は正しく取得できますが、「テキスト」や「テイル属性」、「子要素」は正しく取得できるとは限らないようです。
ですので、注釈に書かれているとおり "end" イベントを使うほうが間違いないでしょう。
さて、プログラムに戻ります。
まず、CSVファイルの先頭行にヘッダーを付けるため、行数カウンターとして扱う変数 i を初期化します。
出力用の CSVファイルをオープンします。ファイルアクセスモードは「w」(書き込み専用)、余計な改行を入れないように newline='' のオプションを指定しています。また、with構文にすることでファイルのクローズを省略しています。そして csv.writer関数に出力ファイルのファイルオブジェクトを渡して、writerオブジェクトを作成します。
XMLを xml.etree.ElementTree.iterparseで解析した結果の contextの要素を forループで取り出します。 contextは イベントと要素のペアのイテレータオブジェクトですので、 for文で contextの要素を変数 event と elem に直接取り出しています。 contextには 'end'イベントしか取得しておらず、また、これ以降にイベントを条件判定などで使うこともないので、「for _, elem in context:」というように「event」を「_」に変更して、値を捨てても構いません。
要素のタグ名が「product」かどうかを判定します。商品マスタの商品情報を示すタグが「<item>」と「</item>」でしたらコードの 'product'を 'item'に、「<商品詳細>」と「</商品詳細>」でしたら '商品詳細'に変更してください。
最初の行を処理するとき、つまり行数カウンターが 0のとき、ヘッダーを作成します。elemのすべての要素のタグ名のリストを作成して writerオブジェクトの writerow関数でCSVファイルに出力します。「[data.tag for data in elem]」は内包表記と呼ばれる記述方法で、下記の for文を一行に集約したものです。内包表記についてはここでは詳しく触れませんが、Pythonプログラムを高速化するには必須の記述テクニックです。
続いて、elemのすべての要素のデータ(text)のリストを作成し、それを writerオブジェクトの writerow関数でCSVファイルに出力しています。そして、行カウンター iをインクリメントし、elem.clear()で elem変数を初期化します。この clear関数は、リストや集合、辞書といったデータ型のオブジェクトの要素をすべて削除するものです。この初期化を行うことで、メモリの消費を抑制しています。「elem.clear()」の次行は空のままで Enterキーを押します。対話モードでは、通常、入力した行ごとに命令が実行されますが、withや forはその句のブロックが閉じた時点で実行されます。
コメントアウトしている print文は、forループの中で何行目を処理しているかをコマンドプロンプト画面に表示するものです。行カウンター「i」の値を同じ位置に表示したいので、「end=''」オプションで改行を抑制し、「\r」(キャリッジリターン)で同じ行の先頭にカーソルを戻しつつ「i」の値を出力しています。必要に応じてコメントアウト(先頭の「#」)を外してください。筆者のPCで、10万件の商品マスタを処理するとき、この printを有効にすると平均12秒、無効だと平均4秒でした。ご参考までに。
最後の printはおまけ的なものですが、処理件数を標準出力に出力しています。
Pythonの対話モードを終了するときは、Ctrlキーと「Z」キーを同時押しして Enterキーを押します。
以上で XMLファイルを CSVファイルに変換する Pythonプログラムの説明は一旦終わりですが、このプログラムには欠点があります。しかし、その欠点は後で説明するとして、まずはこれまで対話モードで実行してきた Pythonプログラムを、プログラムらしく実行しています。
Pythonスクリプトファイルを実行する
メモ帳などのテキストエディタを開いて、この記事の先頭のコード「import csv」から「print(f'\r出力行数:{i:,}')」までのすべて行を記入し、「xml2csv.py」というような名前を付けて保存します。ファイルの拡張子は「.py」とするのが通例です。そして、コマンドプロンプトで python xml2csv.py と入力して Enterキーを押すと実行することができます。
もし実行中に強制終了したい場合は、 Ctrlキーと「C」キーを同時押ししてください。
このコードの課題とは?
さて、話を戻して、このプログラムには問題があるといいましたが、それは、XMLファイルの要素の種類や数が一律とは限らないということです。例えば、データベースから XMLファイルを生成するシステムが、データベースの nullの項目を「<項目名/>」または「<項目名></項目名」というようにデータが空であることを明示してくれる場合もあれば、タグすら出力してくれない場合もあるということです。
上記のサンプルを例にとると、 1つめの「product」には「supplier」タグがありますがデータは存在しません。2つ目の「product」では「sale_price」というタグおよびデータがありますが、1つめの「product」には「sale_price」というタグそのものが存在しません。 また、「product_image」の項目のように、画像(ファイル名)を 1つしかもっていない商品もあれば、複数の画像をもっている商品もあります。故に、XMLデータの最初のデータを基に CSVファイルのヘッダー行を作ってしまうと項目(列)が足りないという不具合が起きる可能性があります。
だいぶ長くなってしまったので、この問題の解決方法はまた後日。ではまた!
サービス内容や事例など | ご相談・お見積りはお気軽に |
トランスコスモスのShopify構築・運用支援サービスはこちら













