

R、RStudioのインストールとデータ加工
サービス内容や事例など | ご相談・お見積りはお気軽に |
これまでは汎用性が高く昨今人気のあるPythonについてご紹介してきましたが、Pythonによる統計の話の前に、今回は「R言語」について触れたいと思います。「R言語」は統計解析等のデータ加工・データ分析にフォーカスしていてあまり汎用性が高くないこと、またPyrhonに比べて学習コストが高いことから特別お薦めの言語ということでもありませんが、データサイエンティストを目指すなら知っておくべき言語だと思います。
RStudioというRを使うための開発環境を利用して、統計解析、データ分析をやってみます。今回の記事では、まずRとRStudioのインストール手順、RStudioでCSVデータを加工する方法をご紹介します。
R言語の概要
R言語とは?
R言語は、GPL2.0に従って提供されるフリーソフトウェアで、「統計解析、データ分析、グラフ集計を得意とするプログラミング言語」です。
R言語で何ができるの?
R言語は、統計計算・グラフ集計の分野に特化しています。統計解析分野において、簡単なコードで複雑な統計計算を実施できる「パッケージ」の種類も豊富です。時系列分析・機械学習・バイオインフォマティクスなどの分野でも活用されています。データ分析やCSV加工をする場合に利用可能です。
R言語とPythonの違いは?
PythonもR言語と同じくGPL2.0に従って提供されるフリーソフトウェアです。実は、R言語で実行できる多くの処理はPythonでも処理可能です。Pythonは統計処理の「ライブラリ」も豊富です。さらに、Pythonは統計計算の分野だけでなく、Webサービスの構築やアプリ開発など幅広い分野で利用されています。R言語はデータ分析、グラフ集計の面で非常に優れています。統計分野のパッケージ、関数も豊富で統計解析に適した命令体系も持っているので上手く活用することで迅速かつ確実な開発を実現できます。求める解析手法を実現できる関数が用意されているため短いコードを書くだけでもデータ分析を行うことができます。分析能力を高めたい人にお薦めです。
Python | R | |
用途 | データ分析、ソフトウェア開発もできる言語 | 統計解析に特化する言語 |
料金 | 無償 | 無償 |
学習対象者 | プログラマ、エンジニア、データ分析者、 | データ分析者、研究者 |
強み | データ分析、実装の汎用性が高い | 統計解析に強い |
弱点 | Rほど統計ライブラリは多くない | ライブラリ間の依存関係があり |
R初期設定
本記事では、Windowsのみの手順を記載します。
①Rのインストール手順
Rのインストールファイルをダウンロードするために、次のサイトに移動します。
R: The R Project for Statistical Computing
「download R」のリンクをクリックします。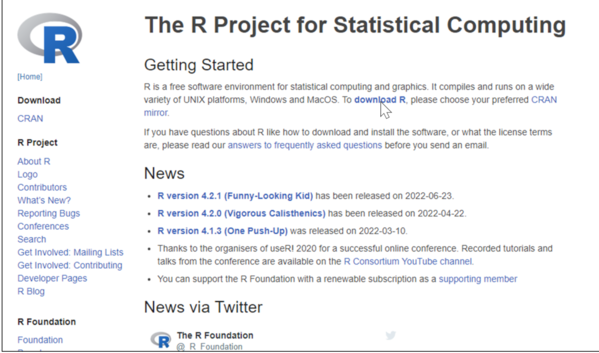
どこからダウンロードするかを選びます。Rのファイルは全世界に配置されています。
ここでは「https://cloud.r-project.org/」を選択します。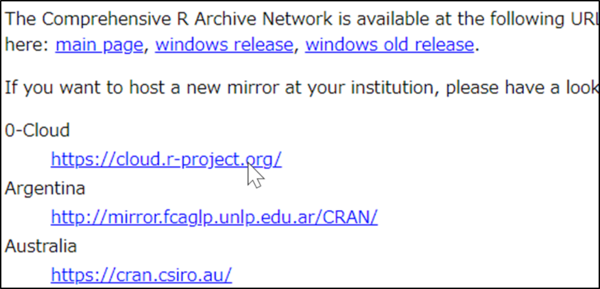
「Download R for Windwos」をクリックします。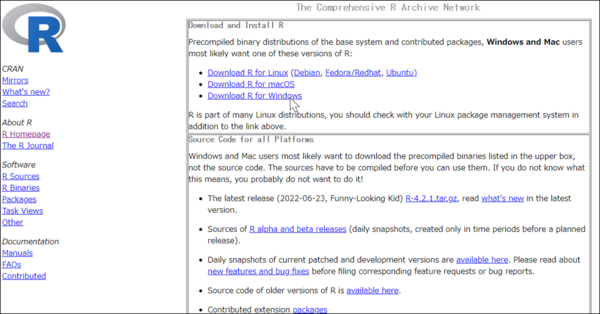
初めてのインストールのため、基本パックの「base」をクリックします。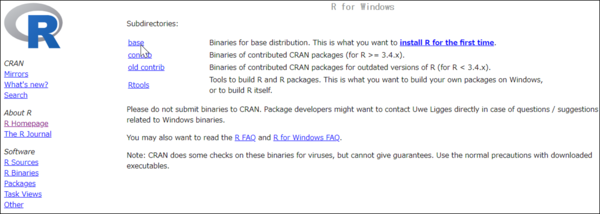
最新版の「Download R-4.2.1 for Windows」をクリックすると、ダウンロードが開始されます。
ダウンロードしたファイルを実行して、利用規約を確認し画面に基づいてインストールを行います。
利用言語を選択します。
ライセンスについての情報が表示されます。
問題ない場合は、「次へ」をクリックします。
任意のインストール先を指定して「次へ」ボタンをクリックします。
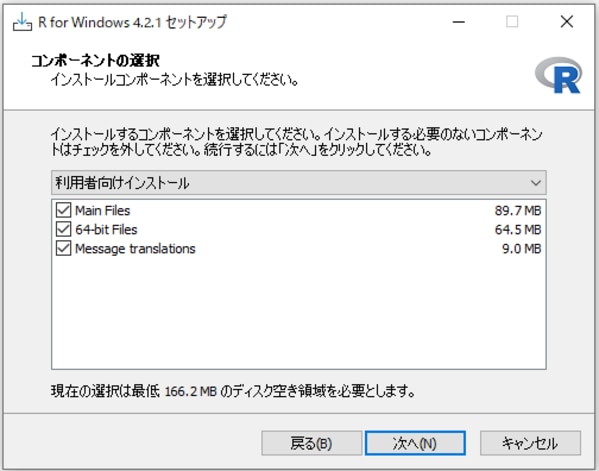
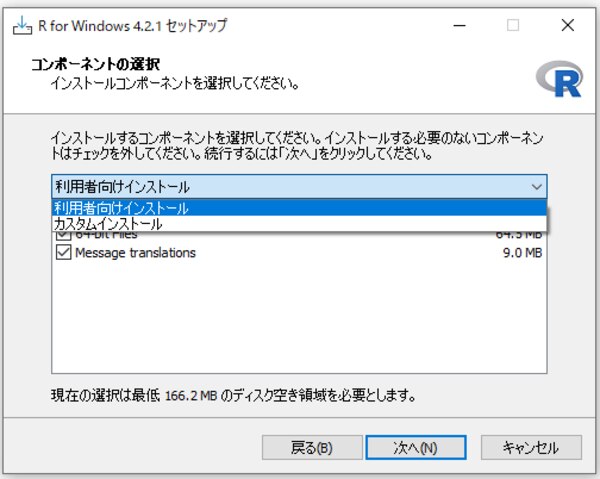
インストールコンポーネントを選択します。
ここでは「利用者向けインストール」を選択します。
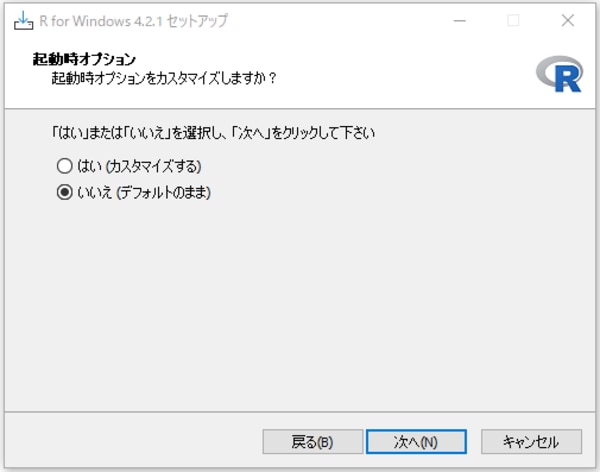
起動時オプションについては、デフォルトのままでそのまま「次へ」をクリックします。
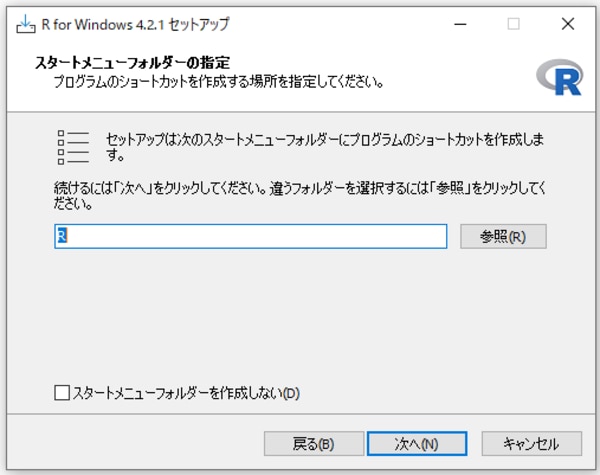
プログラムのショートカットを作成する場所を聞かれますが、このまま進みます。
続いて、オプションの選択画面が表示されます。任意のオプションを設定したら「次へ」ボタンをクリックします。インストールが実行され完了画面が表示されたらインストール完了です。
②RStudioのインストール手順
https://www.rstudio.com/products/rstudio/download/
料金プラン(本記事では無料プランを選択します)
ダウンロードしたファイルを実行し画面に基づいてインストールしてください。
任意のインストール先を指定して「次へ」ボタンをクリックします。
ショートカットを作成するスタートメニューのフォルダを聞かれますので、任意のフォルダを選択し、「インストール」ボタンをクリックします。
上記画面が表示されたら、インストール完了です。
RStudioでは、自分に合った使いやすい設定でカスタマイズを行うことができます。
以下に筆者がオススメする設定をご紹介しますので、参考にしてみてください。
メニューバーからToolsを選択し、Global Optionsを開きます。
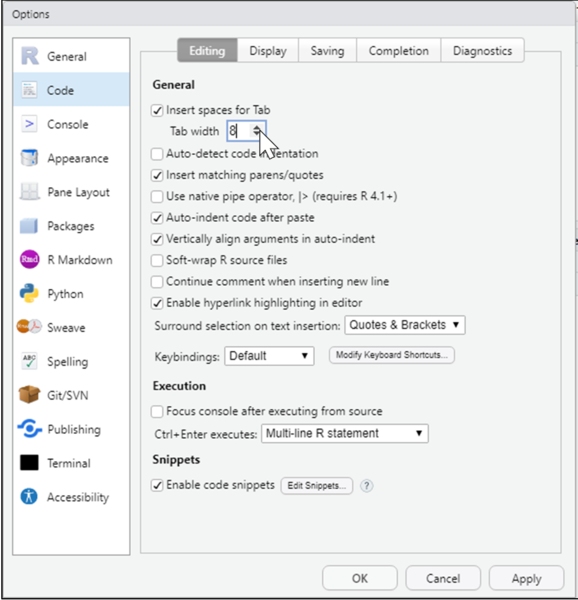
タブ幅の変更
Code(コード) > Editing(編集)を選択し、「Insert spaces for Tab」のTab widthを8に変更します。これによりコードのタブ幅が変わります。
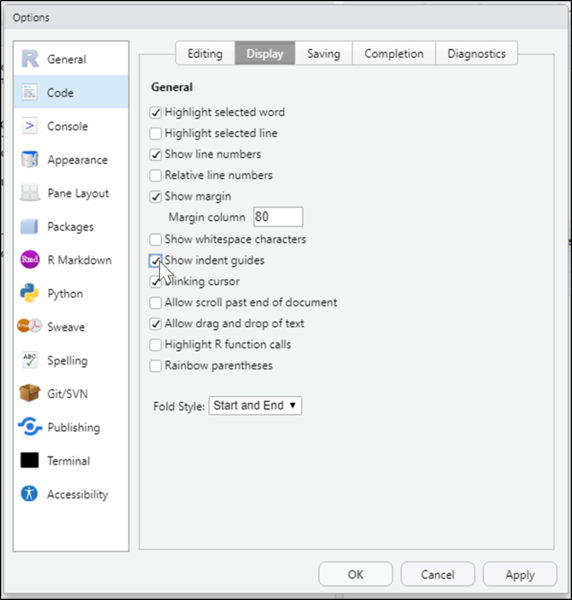
インデントガイドの表示
Code(コード) > Display(表示)からインデントガイドをONにして表示させます。
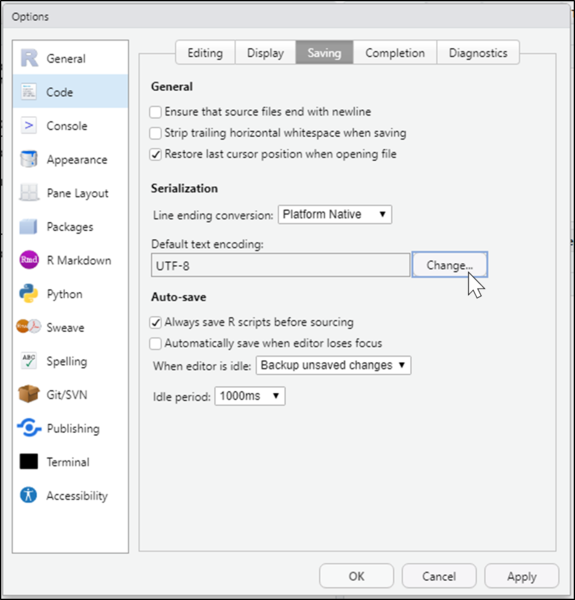
テキストエンコーディングの変更
Code(コード)> Saving(保存)からデフォルトのテキストエンコーディングを「UTF-8」にします。
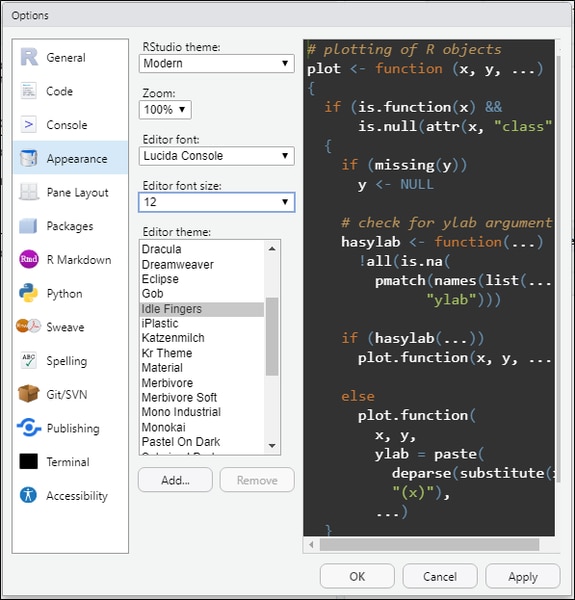
フォントサイズとエディタテーマの変更
Appearance(外観)からフォントサイズを「12」に、エディタテーマを「Idle Fingers」に変更します。
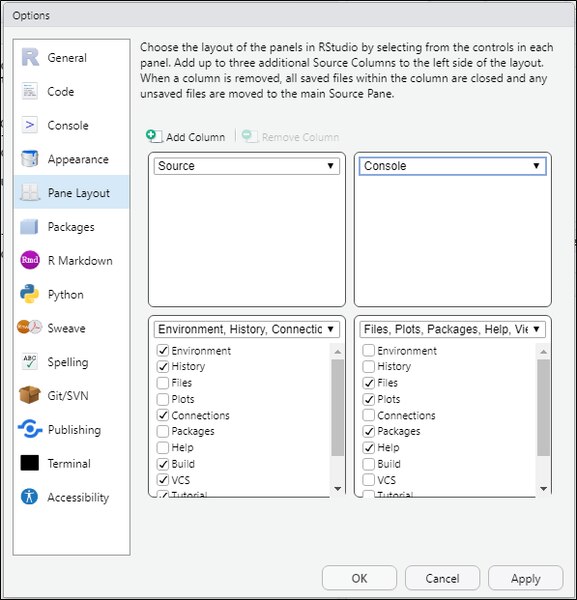
パネルレイアウトの設定
Pane Layout(パネルレイアウト)を下記設定にします。
データ加工のためのスクリプト作成
パッケージインストール(初回のみ)※必須
各パッケージについて簡単な説明をします。
dplyr | 表型データの操作に特化した R のパッケージ 表型データの中からサブセットを抽出したりする関数や抽出したサブセットに対して集計を行う関数などが多数用意されている。 |
tidyr | データフレーム(正確には tibble 型のオブジェクト)の並べ方を展開したり、集約したりする際に利用する関数が多く用意されている |
rpart | 決定木を行うためのもの |
partykit | ツリー構造の回帰および分類モデルを表現、要約、および視覚化するためのインフラストラクチャを備えたツールキット |
rpart.plot | 'rpart'モデルをプロットする 'rpart'パッケージのplot.rpart()とtext.rpart()を拡張する |
ggplot2 | “Grammer of Graphics”のコンセプトを実装したパッケージ グラフィックの構成要素を意識したレイヤー構造を持つ |
readxl | ExcelファイルをRに読み込む |
bnlearn | ベイジアンネットワークのグラフィカル構造を学習し、それらのパラメーターを推定し、いくつかの有用な推論を実行するためのRパッケージ |
lavaan | 確認的因子分析、構造方程式モデリング、潜在成長曲線モデルなど、さまざまな潜在変数モデルを適合させる |
bit64 | シリアライズ可能なS3アトミック64ビット(符号付き)整数を提供 |
openxlsx | JAVAに依存せずxlsxファイルを読み込むことが出来る xlsファイルには非対応 |
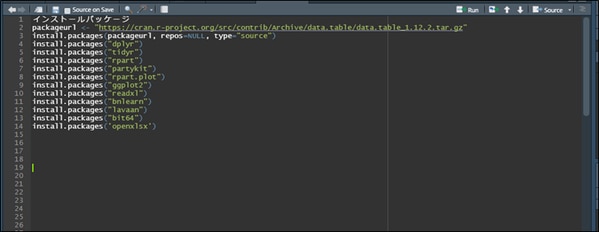
RStudioを起動するとエディタが開きますので、コードを記入し、行ごとにキーボードのF5キーか「Run」ボタンを押して実行します。
毎回実行する必要があるコード
rm(list=ls(all=TRUE))では全オブジェクトを削除します。
gc()はガベージコレクションのことで、メモリの解放を行います。2回連続で実行している理由は、直前の結果を保存している隠しオブジェクト.Last.valueが大きい場合に1回目でgc()の返り値により上書きされ、2回目のgc()で領域が解放されるからです。
library()では、必要なパッケージを呼び出しています。
最後にhome <- 'C:/Temp'で指定のフォルダを「home」に代入し、setwd(home)で作業フォルダを移動しています。
コードを記入し、行ごとにF5かRunを押します。(ホームフォルダーは自由に設定可能です)
CSVを加工するために、まずはCSVデータを読み込みが必要です。
CSV取り込み(文字コード指定) ※事前にCSVを用意する必要があります。

header = T | ヘッダー表示 (T 表示 /F 非表示) |
colClasses = 'charactor' | 全ての項目を文字列として読み込むようなこと |
na.strings ="" | Rの欠損値NAに変換する場合はna.strings="NULL"やna.strings=c("", "NULL")を指定する。 |
encoding="UTF-8" | エンコード=UTF-8に指定 |
読み込まれたCSVデータをその場で確認することが可能です。
ヘッダー追加
下に別のCSVファイルと結合するためのヘッダーが無い場合にヘッダーを付与する例です。

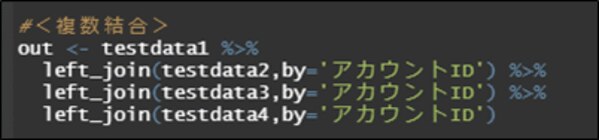
データを複数結合(left_join, inner_join, right_join, full_joinが可能)
4つのCSVデータを結合する例とします。
「testdata1」、「testdata2」、「testdata3」、「testdata4」のleft_joinになります。結合キーは「アカウントID」とします。左側(第一引数)を優先して結合します。
<-:代入演算子
%>% :パイプ演算子と呼ばれ、左側のオブジェクトを右側の関数の第一引数に渡す
条件付きフィルター
file2はfileのデータからフラグ='flag1' と フラグ='flag2'のみにフィルターし、上書きされます。

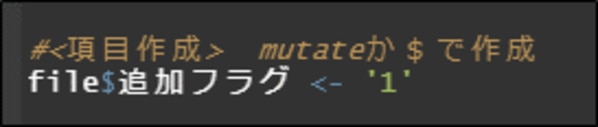
CSVデータに追加項目作成(mutateか$で作成)
新規項目追加する場合はmutateを利用します。 fileのデータの全てのレコードに新規「追加フラグ」というヘッダー項目を1の値で付与します。
重複削除例
file3は、重複された「アカウントID」の全てのレコードを削除します。
file4は、file3リストのユニークレコードのみ
加工されたfile4を書き込み、ファイルを出力する

出力時文字コード指定

write.csv | CSVファイルを出力する |
out | 出力する変数 (自由定義された) |
row.names =F | 行名の指定をしない |
quote=F | quote:””を出力なしの指定 |
fileEncoding="UTF-8" | エンコード=UTF-8に指定 |
R言語で加工されたCSVデータでデータ分析する
①R言語での統計解析例
R言語に標準添付されているデータセット「VADeaths」を使います。
VADeathsの中身は、50歳〜74歳の年齢を5段階に分けて、その死亡率を田舎(rural)、都会(urban)の男性(male)と女性(female)別に分けて集計したデータです。

統計結果

「Death of Rural Male = 田舎の男性の死亡率」について、以下の通り縦の棒グラフが表示されます。

R言語はPythonよりも学習コストは高く、統計学の知識がないとデータ解析が難しいですが、データ解析に便利な機能が多く実装されていますので、興味がある方は是非学んでみてください。
長くなってしまったので、次の記事でABテストやデータ分析の方法を紹介します。
サービス内容や事例など | ご相談・お見積りはお気軽に |
トランスコスモスのShopify構築・運用支援サービスはこちら













