

【Shopifyストア運用支援】Jupyter Notebookでレポートを作成する(後編)
前編では Jupyter Notebook の準備と簡単な操作方法を紹介しましたが、後編では実際にデータを読み込んでグラフを作成するところまでを説明します。


matplotlib(マットプロットリブ)
matplotlib がインストールされているかを確認する
Pythonでグラフを作成するには matplotlib を用います。まずは、 matplotlib がインストールされているか、実際に import して確認してみます。インストールされていない場合、下図のようなエラーが表示されます。

仮想環境に matplotlib をインストールする
Jupyter Notebook を実行しているコマンドプロンプトとは別のコマンドプロンプトを開き、jupyter_workspace\Scripts\activate コマンドで仮想環境を有効にして、 pip install matplotlib で matplotlib を仮想環境にインストールします。
あらためて import 文を実行するとエラーが表示されなくなります。
仮想環境を抜ける
matplotlib をインストールした仮想環境のコマンドプロンプトは閉じて構いません。仮想環境だけを抜ける場合は deactivate コマンドを実行しますが、コマンドプロンプトに戻る必要がない場合は、Windows コマンドの exit で一気に抜けられます。
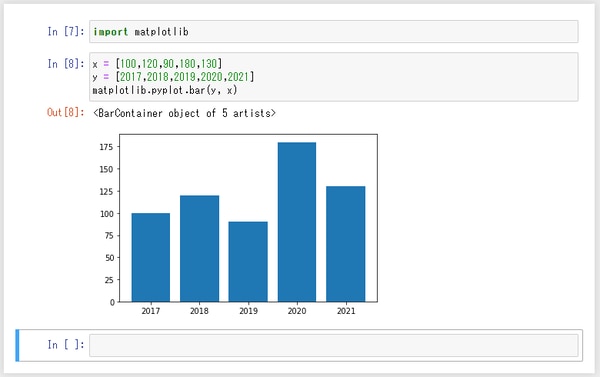
matplotlibで棒グラフを作る
matplotlib.pyplot.bar
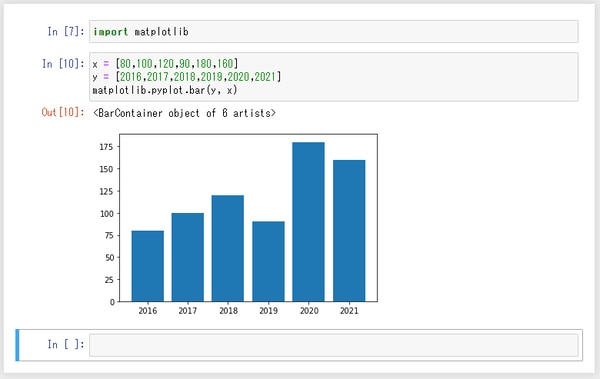
まずは簡単なデータで棒グラフを作成してみましょう。下図の例では、変数 x に売上高、変数 y に年度の数字をそれぞれセットし、それをグラフ化しています。棒グラフは、matplotlib.pyplot.bar を使います。
Jupyter Notebook のセルの行番号
なお、下図は変数 x と y に、2016年度の売上高を追加しています。Jupyter Notebook は、実行した行(セルといいます)の行番号がインクリメントされていきます。上図で「In[8]」、「Out[8]」と表示されている部分が、下図では「In[10]」、「Out[10]」に変わっていることが分かると思いますが、これは「In[10]」のセルが2回実行されたことを表しています。これは、前方のセルを更新・実行し、後方のセルを実行していないと、数字が逆転している状態になるため、修正が反映されていないセルに気づきやすくなっています。
Jupyter NotebookのRe-Run(再実行)

このボタンをクリックすると、「Restart kernel and re-run the whole notebook?」というダイアログが表示されます。「Restart and Run All Cells」ボタンをクリックすると Jupyter Notebook がリスタートされ、すべてのセルのコードが先頭から順に実行されます。Jupyter Notebook のリスタートにより、インクリメントされていたセルの行番号は初期化されます。
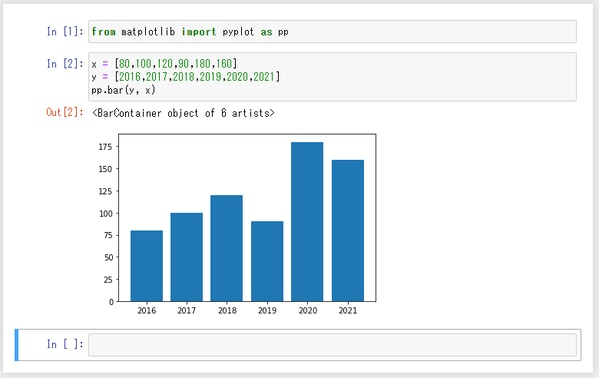
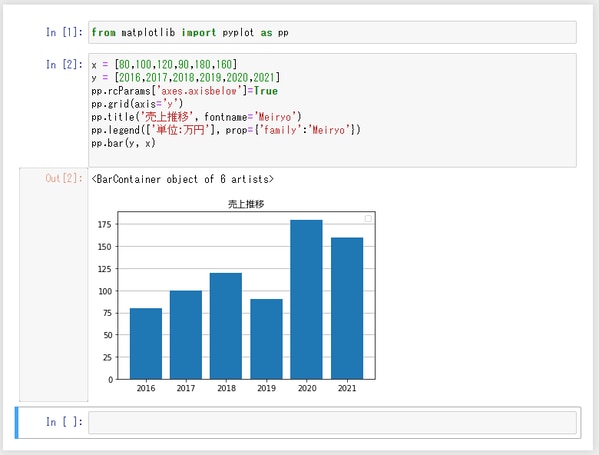
棒グラフの修飾
下図は棒グラフを修飾する代表的なオプションをいくつか追記したものです。各オプションの詳細は割愛します。Googleなどの検索エンジンで「matplotlib リファレンス」などと検索すると色んなサイトがヒットすると思います。また、matpltlib に関する書籍もたくさん出ておりますので、気に入ったものをご購入いただくのもよいでしょう。
参考サイト
https://matplotlib.org/ (英語)
https://amorphous.tf.chiba-u.jp/lecture.files/chem_computer/12_Matplotlibの使い方/12.html
さて、上記のような少量のデータでグラフを作るなら Excel のほうが早いと思うかもしれません。しかし Python でやるべきは、毎回 、CSVファイルを Excelで開いてデータを整形し、グラフ範囲を指定して、グラフの見栄えを良くして・・といった繰り返し作業にかかる無駄な時間を減らすことにあります。
そして、Excelでは扱えないような大量のデータでも瞬時に処理してしまおうというものです。
pandas
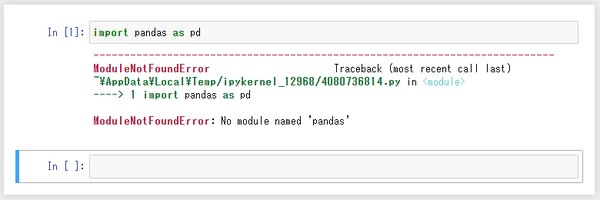
大量データの加工に必須なのが pandas というパッケージです。pandas がインストールされているか、import で試してみます。インストールされていないと下図のようなエラーが出ます。
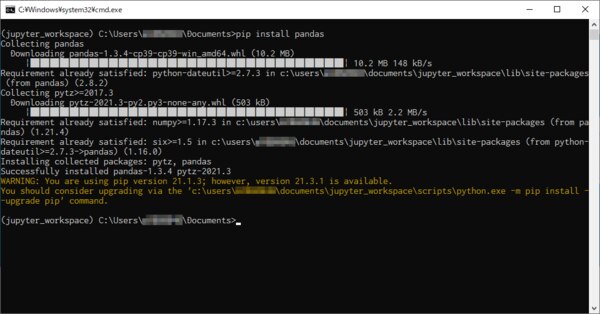
仮想環境に pandas をインストールする
コマンドプロンプトで仮想環境を有効にして、pip install pandas で pandas をインストールします。pandas で Excel ファイルの読み書きをする場合などは他にもインストールしなければならないパッケージもありますが、今回は省略します。
テストデータの準備には、『個人情報テストデータジェネレーター』を利用させていただきました。会員情報のようなテストデータを一度に1万件まで生成することができます。
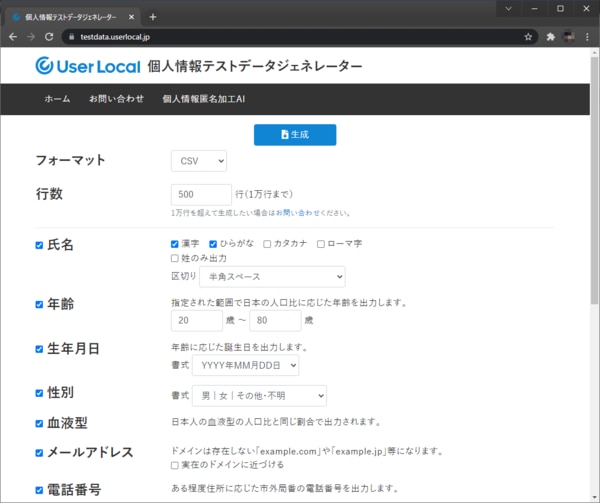
出典:https://testdata.userlocal.jp/
pandas.read_csv
import pandas as pd で pandas をインポートし pd という別名をつけています。「pd」という別名は慣習的なもので、特に決まりがあるものではありません。そして、pd.read_csv メソッドで CSVファイルを読み込み、それを変数 df に代入します。この df はデータフレームというオブジェクトの略を変数名としています。
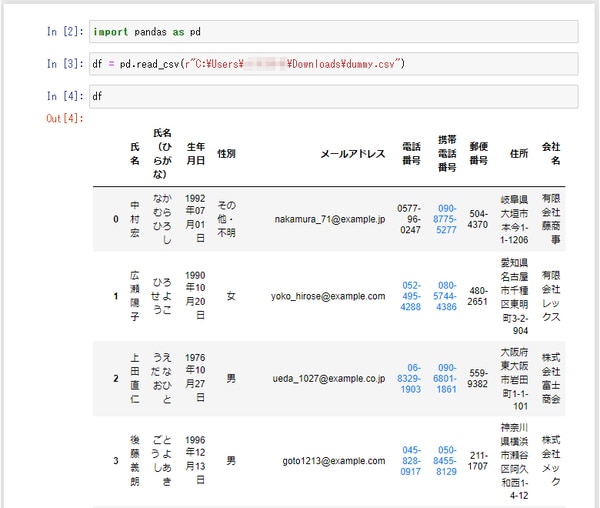
pandas.read_csv で10列×1万件の CSVファイルを読み込んだときにかかる時間を計測してみました。約0.08秒。Excelを起動するより断然早いですね。なお、筆者の社用パソコンのスペックは、CPUが i3-8130U@2.20GHz、メモリ16GB、東芝製のハードディスクです。(SSD換装したい・・)
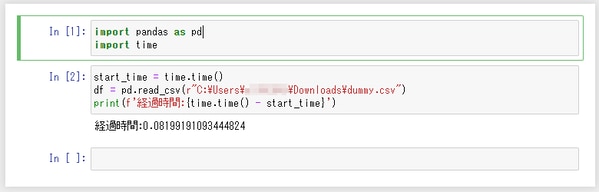
read_csv には、CSVファイルの区切り文字やクォーテーション記号を指定したり、先頭のn行をスキップしたり、列ごとのデータ型を指定する等の様々なオプションがありますが、本稿では割愛します。詳しくは https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html (英語)などをご覧ください。
groupby().count()
データフレームオブジェクトは groupby() というメソッドがあり、これでデータをグルーピングすることができます。また、グルーピングしたデータフレームを count() メソッドでカウントすることができます。下図の例では、まず「df_g = df[['氏名', '性別']]」で、変数「df_g」にデータフレーム「df」の「氏名」と「性別」の列(pandasではシリーズといいます)を抽出してコンパクトにし、そして「df_g」を「性別」でグルーピングしてカウントを求めることで、男女別の人数を割り出しています。CSVファイルの読み込みから男女別人数を求めるまでの経過時間は0.38秒でした。
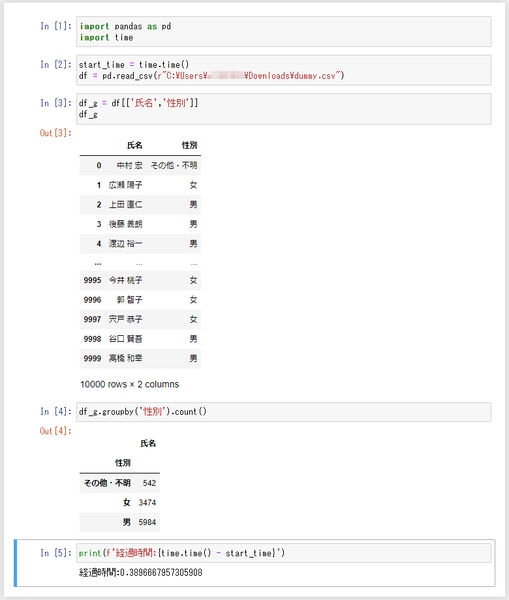
pandas の詳細は公式サイト(英語)をご覧ください。また、公式サイトの一部を日本語に機械翻訳したとされる Pandasユーザーガイド「データの索引と選択」(公式ドキュメント日本語訳) も参考になると思います。
matplotlibで円グラフを作成する
matplotlib.pyplot.pie
円グラフを作成するには matplotlib.pyplot.pie を使います。その前に・・・グラフの凡例などに日本語を使うと文字化けするので、 japanize_matplotlib を使うと良いようです。仮想環境に pip で japanize_matplotlib をインストールした上で、下図のように import します。そして、5行目は、前述のグルーピングした結果を dict で辞書型にキャストして、6行目で matplotlib.pyplot.pie を使って円グラフを生成しています。辞書型の変数 dict_gg の values() メソッドは、辞書から値を抽出し、keys() メソッドは辞書のキーを抽出します。
matplotlib.pyplot.pie の autopct オプションは円グラフの各比率を表示する%書式を指定します。下図の例では、 %.2f で小数点以下2位までの実数表示、末尾の %% は %記号のエスケープ( %% で % 一文字を表す)処理を表します。また、 startangle は円グラフのスタート位置を角度で指定するオプションです。90度を指定することで、時計の12時方向からスタートする円グラフを作成することができます。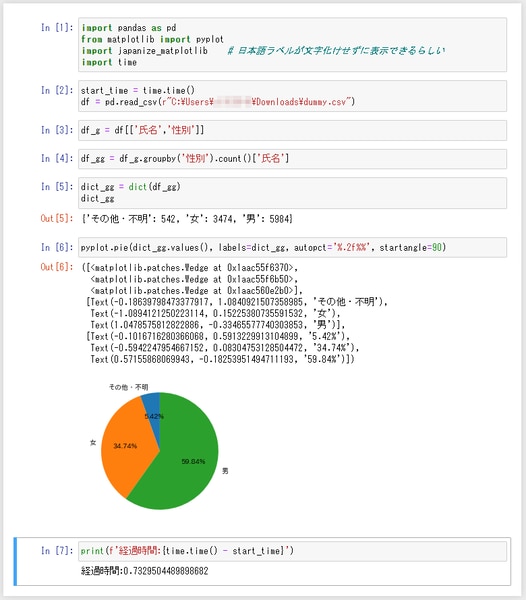
1万件の CSVファイルを読み込み、円グラフを作成するまでにかかった時間は 0.73秒。Excelでこのようなグラフやレポートを作るとしたら何十倍も時間がかかることと思います。それにデータが夕方にしか集まらなくて、レポートを作るのに夜遅くまで残業しなければならないとか。そういう皆さんに Pythonで楽をしてほしいなと思ってます。それではまた!















