

【Shopifyストア運用支援】pandasで大量のテストデータを一気に作成する
サービス内容や事例など | ご相談・お見積りはお気軽に |
テスト用の大量の注文データを、簡単かつ高速に作成する方法を紹介します。Visual Studio Code(VSCODE)で Jupyter Notebookを起動して、Pythonで pandasを使いますので、はじめてこのブログをご覧になる方は、過去の記事をご覧いただけると嬉しいです。このテストデータは今後予定しているレポート編集の記事で使っていく予定です。
VSCODEで Jupyter Notebookを起動する
VSCODEを起動する
VSCODEを起動して、Ctrl+K、Ctrl+Oで Jupyter Notebookをインストールした仮想ディレクトリを作業ディレクトリとして開きます。ターミナルで仮想環境をアクティベートします。
Jupyter Notebookの新しいファイルを開く
VSCODEのメニューから「ファイル」、「新しいファイルを開く」を選択します。
新規作成するファイルの種類を問われたら Jupyter Notebookを選択します。

VSCODEのエディターに Jupyter Notebookのラインエディターが開きます。

pandasをインポートする
import pandas
Jupyter Notebookの 1行目に import pandas as pdと入力します。VSCODEはサジェスト機能が有効なため、入力途中で候補が表示されたら Tabキーやカーソルキー(矢印キー)で候補を選択して Enterするとオートコンプリートされます。
もし、pandasがインストールされていない場合はエディターが警告表示しますので、ターミナルで pip install pandas を実行して pandasをインストールしてください。
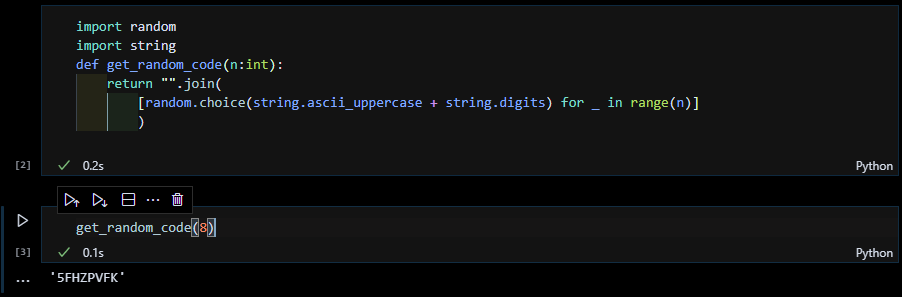
商品マスタを作成する
商品番号用にランダムコードを生成する関数を作成
乱数を発生させる randomと文字型データを操作する stringをインポートします。いずれも Pythonの標準ライブラリ(モジュール)なので、これらを改めてインストールする必要はありません。
そして def get_random_code(n:int): で関数を宣言します。括弧内の n:intは引数 nが int型であることを示しています。また、ここでは記載していませんが、戻り値の型を示す場合は、def 関数名(引数) -> str: といった書き方をします。
Pythonは変数も関数もオブジェクトであり、そのオブジェクトに代入されている値の型は Pythonが自動判別します。また、仮に型宣言しても別の型の値を代入することができてしまうので、データ型を宣言することにあまり意味はありませんが、デバッグには役立つことでしょう。
戻り値は、'ABCDEFGHIJKLMNOPQRSTUVWXYZ'を表す string.ascii_uppercaseと '0123456789'を表す string.ascii_digitsを結合した中から random.choiceで1文字取得する処理を、リストの内報表記で n回ループして、1文字× n要素のリストを作成。それを ""(空文字)で joinして、n桁の文字列としています。
ランダムな商品IDを pandasのシリーズにする
pandasには「データフレーム」と「シリーズ」というデータ構造があります。データフレームは二次元の、シリーズは一次元の配列構造となっており、シリーズはデータフレームの列に相当する構成要素でもあります。
pandasのシリーズを作成するには、pandas.Seriesに一次元のリストを渡します。ここでは、リストの内包表記で前述の関数を用いて 200個の商品番号を生成し、それを pandasのシリーズにしています。

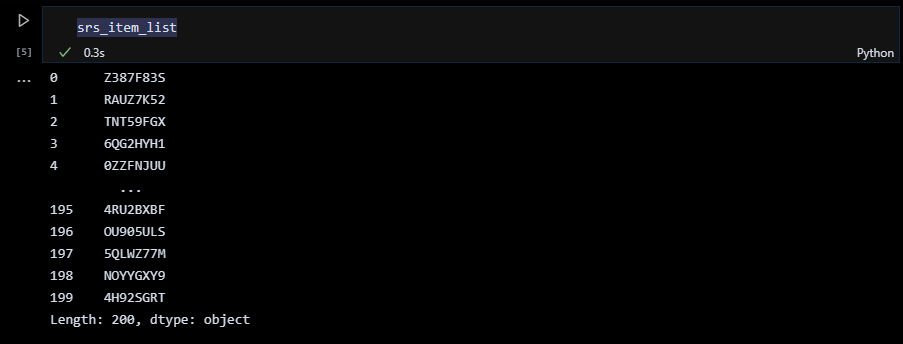
シリーズに名前を付け忘れました。シリーズに名前を付けるには pandas.Seriesの引数で「name = 列名」を指定します。

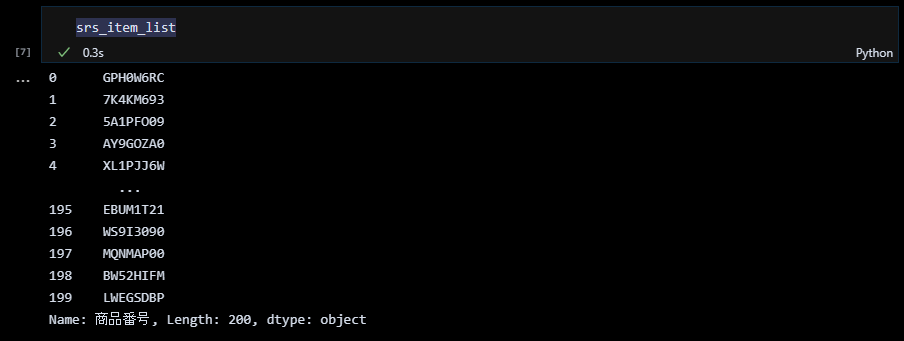
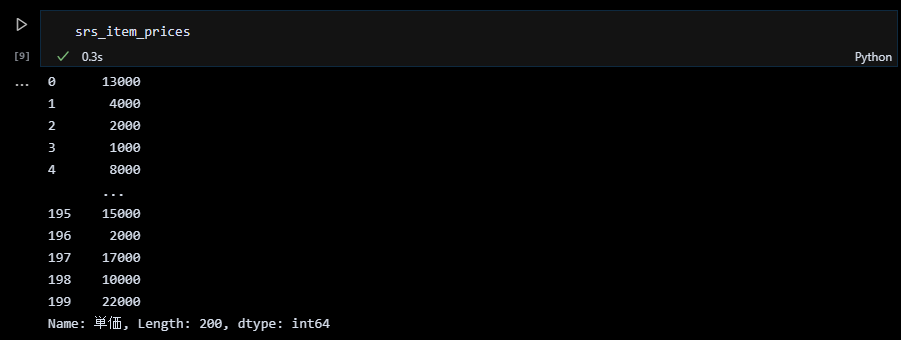
商品単価を pandasのシリーズにする
random.randintを使って適当な商品単価を200個作成して、pandasのシリーズにします。下図の例では、0~30のランダムな整数に1000(千円)を掛けて単価を生成しています。(単価が0円の商品は考えにくいので、ランダムな整数の範囲は 1~30としたほうが良いですね。)

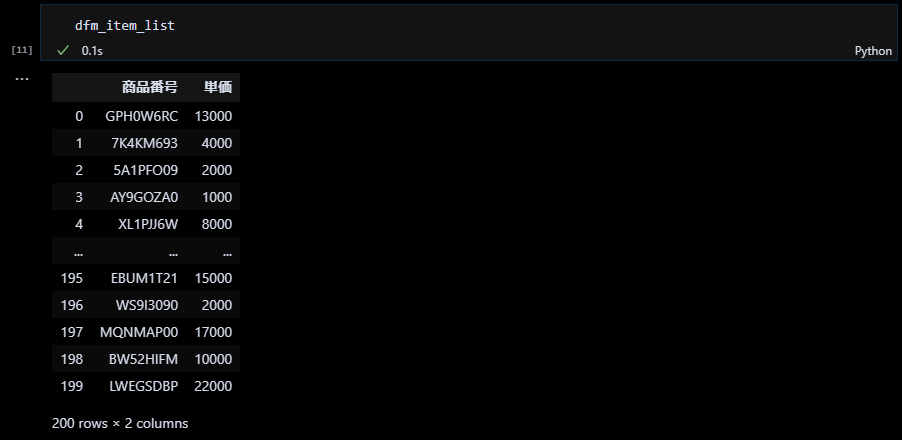
商品IDと単価のシリーズを結合してデータフレームにする
pandas.concat を使い商品IDのシリーズと単価のシリーズを結合します。引数 axis=1は、シリーズを縦方向に結合するか、横方向に結合するかを指定するもので、axis=0(デフォルト)は縦方向、axis=1は横方向になります。

商品番号を基に商品名の列を作成する
データフレーム[列名]で既存の列名を指定するとその列のデータが参照でき、新たな列名を指定するとその列に新たなデータを生成することができます。下図の例では、商品名の列に「テスト商品 」という文字列と商品番号の列の値を結合してセットしています。

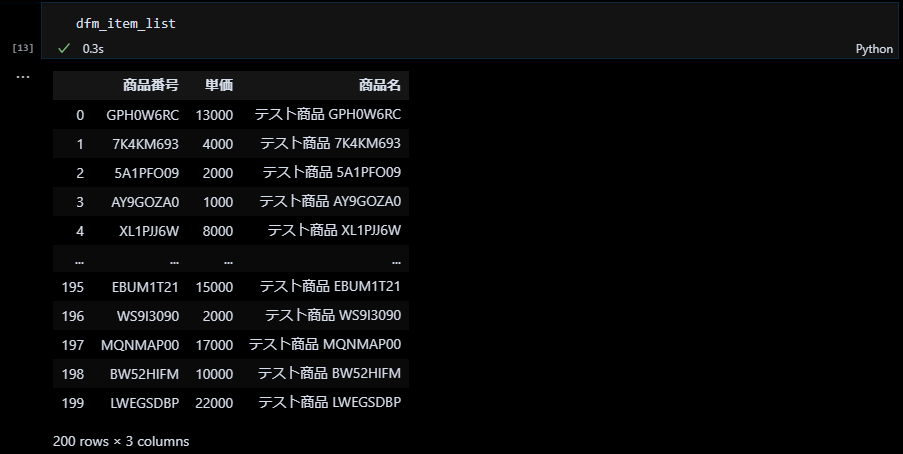
これで簡易的な商品マスタの完成です。
会員マスタを作成する
会員データのCSVファイルを読み込む
以前の記事で取得したテスト用の会員データを会員マスタとして利用します。pandas.read_csvで CSVファイルを指定すると、そのファイルを読み込んでデータフレームにすることができます。Pythonは内部の文字コードが utf-8なので、もし、CSVファイルがシフトJISだった場合は、引数に encoding='sjis' と指定します。
pandas.read_csvの各種オプションはこちら(英語)をご覧ください。


注文データを作成する
datetime.timedeltaと random.randintで注文日のシリーズを作成
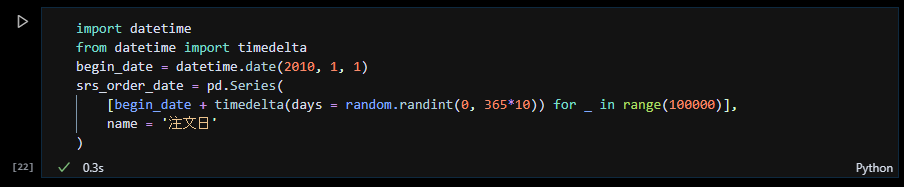
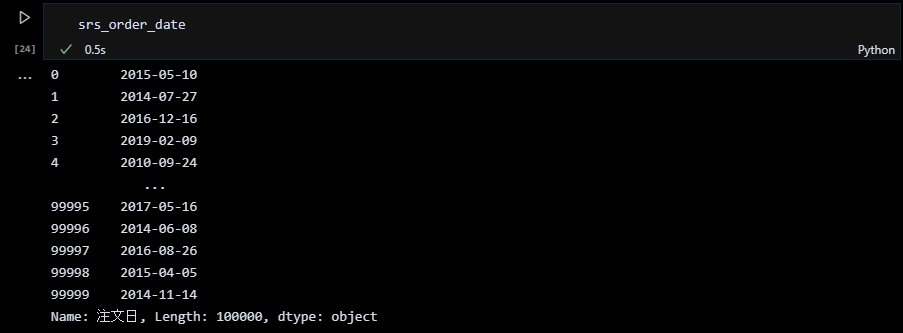
まず、datetimeをインポートし、datetime.date(年, 月, 日)で最も古い注文日を変数 begin_dateに代入。続いて、要素数10万の注文日のリストを生成して pandasのシリーズにします。注文日のリストは begin_dateに datetime.timedeltaで、random.randintで生成した日数を加算しています。なお、random.randintの生成する日数の範囲は 0~365*10、つまり約10年間としています。
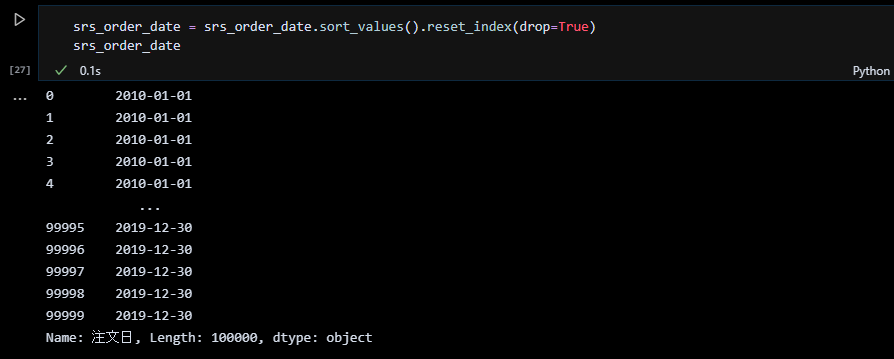
注文日を sort_valueと reset_indexで整列する
10万件(行)の注文日のシリーズを pandas.dataframe.sort_valueでソートし、reset_indexでインデックスを付けなおします。reset_indexの引数 drop=Trueは、これを指定しないと旧インデックスが列になってしまうため、旧インデックスを落とすためのオプションです。
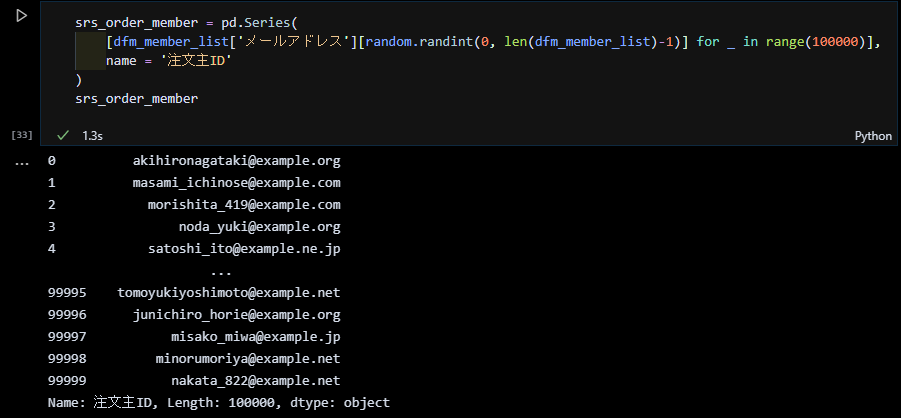
会員マスタを基に注文主IDのシリーズを作成する
会員マスタのデータフレームの「メールアドレス」を注文主IDとします。まずはランダムにメールアドレスが抽出できることを試してみます。

注文主IDのシリーズも10万件作成します。下図の random.randintの範囲を 0~len(会員マスタのデータフレーム)-1 としていますが、これだと毎回 lenが実行されるので、高速化を図るには、前もって len(会員マスタのデータフレーム) の結果を変数に代入して、random.randintの範囲指定にその変数を指定するほうが賢いですね。
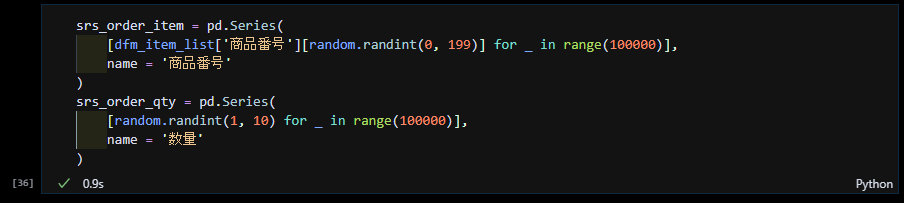
注文データの商品番号のシリーズそして数量のシリーズを作成する
同様に、商品マスタを基に注文データの商品番号10万件のシリーズと、数量の10万件のシリーズを作成します。
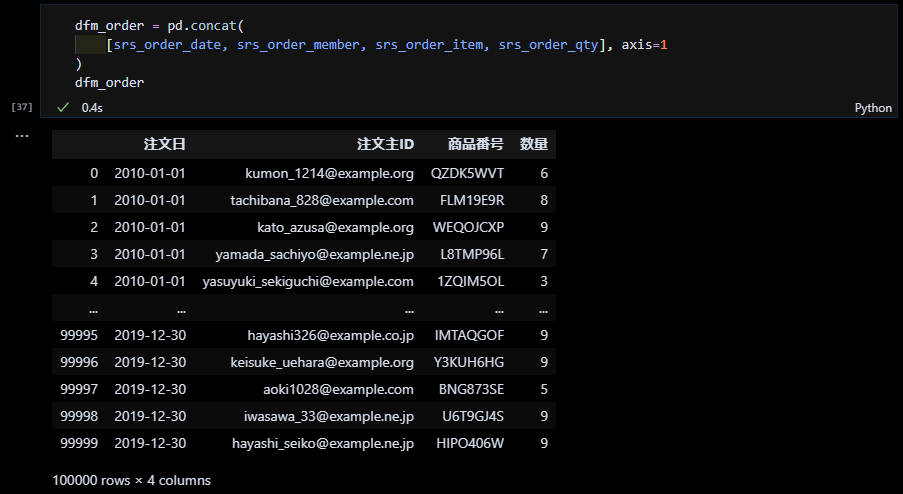
各シリーズを結合して注文データにする
pandas.concatで注文日、注文主ID、商品番号、数量のシリーズを結合して注文データのデータフレームにします。
注文データに商品マスタをマージ
pandas.dataframe.mergeで、注文データに商品マスタをマージします。結合のキーは「商品番号」です。mergeの各種オプションはこちら(英語)をご覧ください。

注文データに単価×数量の金額を追加する
商品マスタに商品名を追加したときと同様、「単価」の値と「数量」の値を掛けて、「金額」の列を追加します。
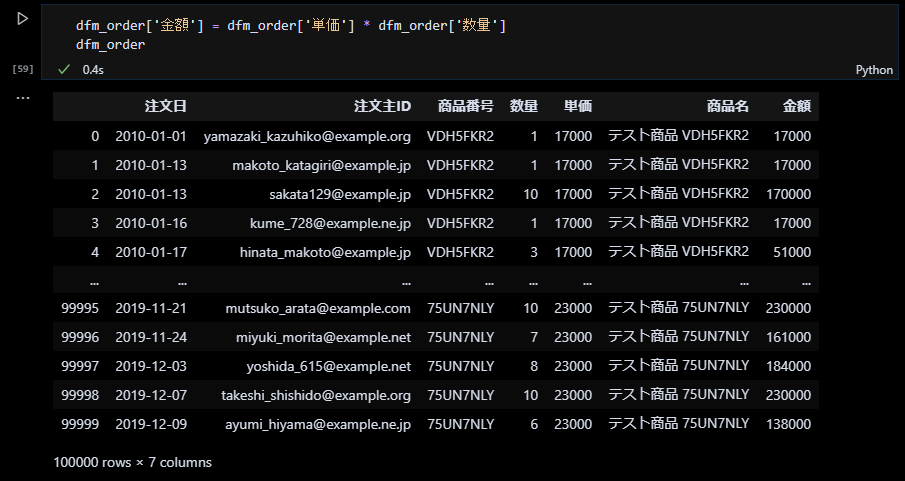
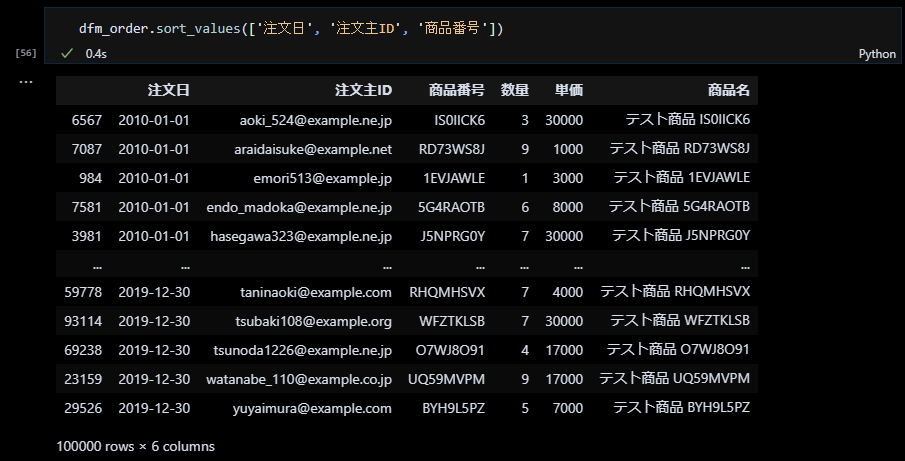
列を整理して見栄えを良くする
pandas.dataframe.reindexで columnsオプションを指定することで列の順序を変えることができます。下図では、併せて sort_valueで「注文日」、「注文主ID」、「商品番号」の順にソートし、インデックスをリセットしています。また、インデックスにも「注文番号」の名前をセットしました。
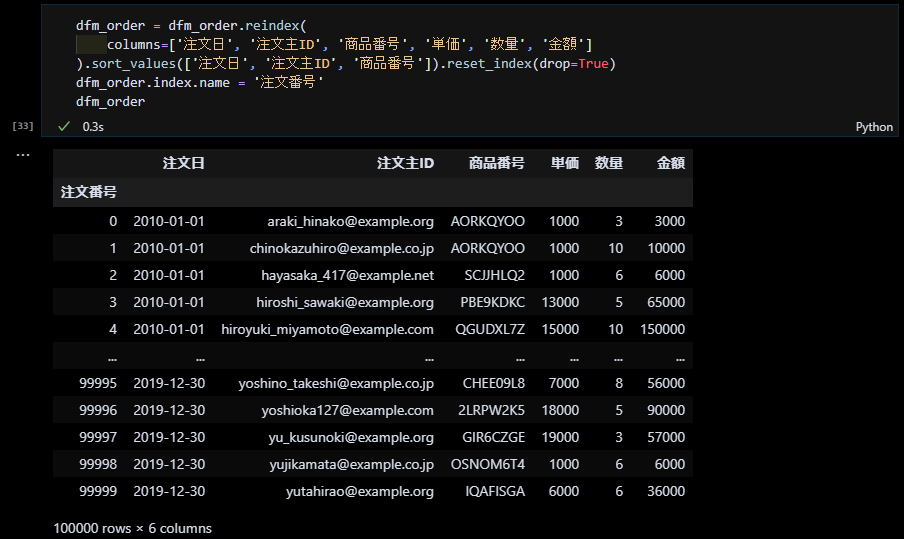
これで注文データの完成です。
注文データをCSVファイルに出力する
pandas.dataframe.to_csv
データフレームを CSVファイルに出力するには to_csvを使います。出力した CSVファイルをExcelで開くには encoding='sjis' または encoding='utf-8-sig'(BOM付utf8)を指定します。

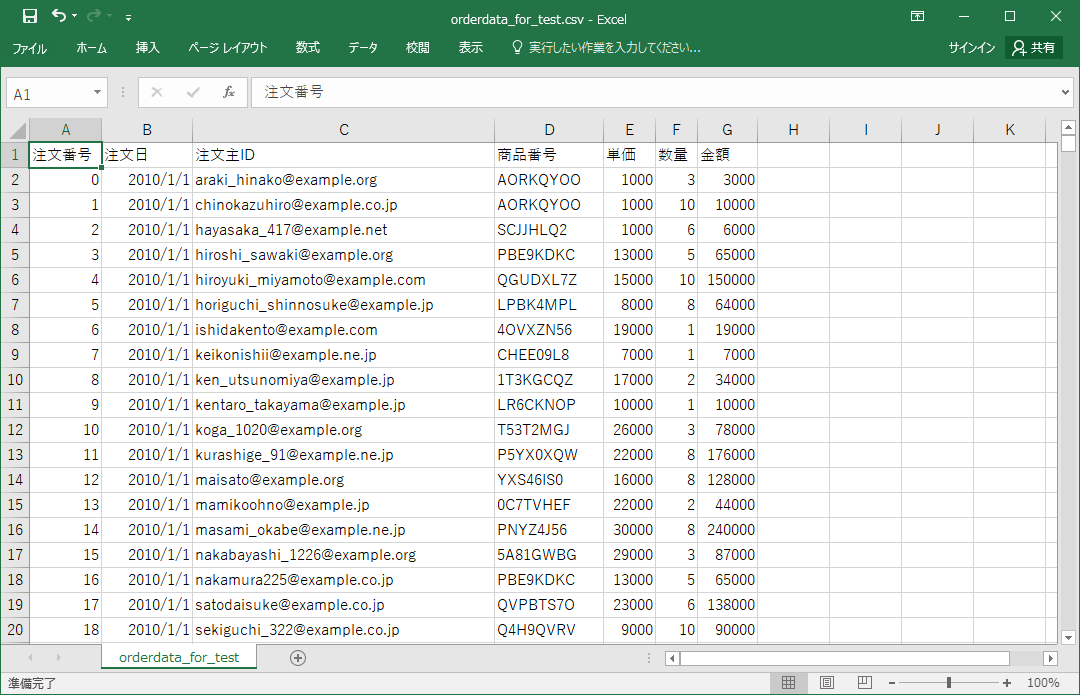
これで10万件のテスト用注文データの CSVファイルが完成です。
Pythonファイル化
VSCODEで Jupyter Notebookをエクスポート
VSCODE上の Jupyter Notebookを保存したあと、「...」をクリックすると下図のようなメニューが表示されます。ここで「export」を選択すると Jupyter Notebookで編集していたコードを Pythonスクリプト(.pyファイル)に出力することができます。
Pythonスクリプトにエクスポートできたら、あちらこちらに散らばっていた importを整理したり、数字でべた書きしていた商品マスタや注文データの行数を定数(※)にして再利用しやすいようにしましょう。
※Pythonに定数という考え方はありませんが、定数的に使うという意味でご理解ください。
今回は pandasを使ったテストデータの作成方法を紹介させていただきました。時間を計測していなかったので感覚的な話になりますが、10万件だと数秒、50万件で30~40秒くらいでテストデータが作成できます。何ヶ所か改善ポイントも見つかっていますので、それらを改善するともう少し早くなるかなと思います。それではまた!
サービス内容や事例など | ご相談・お見積りはお気軽に |
トランスコスモスのShopify構築・運用支援サービスはこちら













